Yeni Kayıt
Yeni Kayıt

 Özel Mesaj
Özel Mesaj


 Görüntülenme
Görüntülenme 












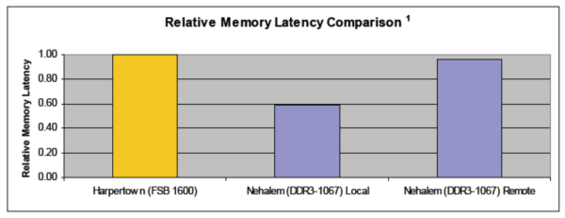
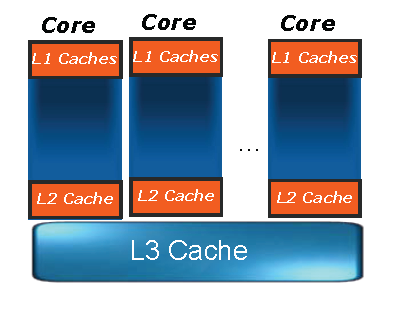

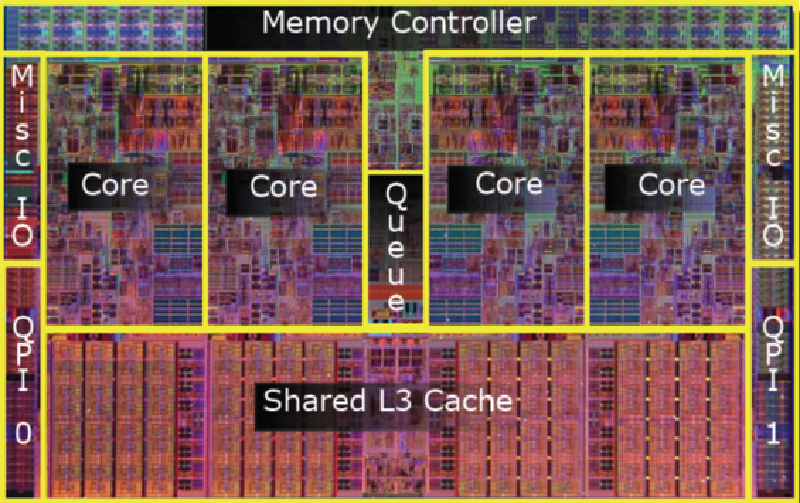
 15 Yanıt
15 Yanıt
 Yanıtla
Yanıtla
 Favorilere Ekle
Favorilere Ekle
 0
0 




















Bildirim
S
@saidakkas




 +1
+1
En az 1.000 Mesaj Yazdı
En az 50 Mention'ı Yanıtladı
En az 50 Forumda Mesajı Bulunuyor
En az 100 Portal Yorumu Yaptı
+1
1 diğer rütbeyi gör
Gönderileri
saidakkas · İşlemci altına konu açtı.
15 yıl
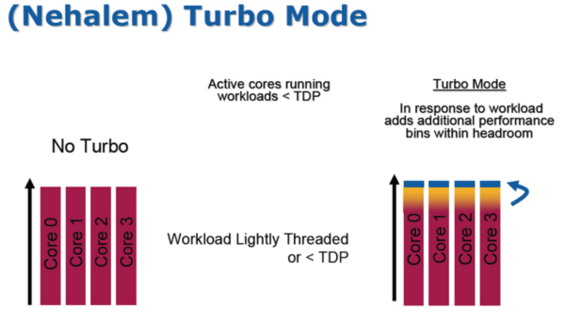
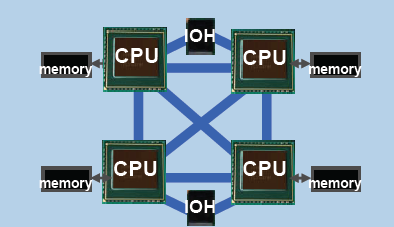
Detaylı bir Nehalem analizi
|
saidakkas · İşlemci altına konu açtı.
16 yıl
İlk üç boyutlu işlemci yeni mimaride 1.4 Ghz'de çalışıyor
|
saidakkas · İşlemci altına konu açtı.
16 yıl
Moore yasasının pabucu dama atıldı, yeni trend TSV
|
|
saidakkas · İşlemci altına konu açtı.
16 yıl
Asus'dan Nehalem için voltaj uyarısı
|
saidakkas · İşlemci altına konu açtı.
16 yıl
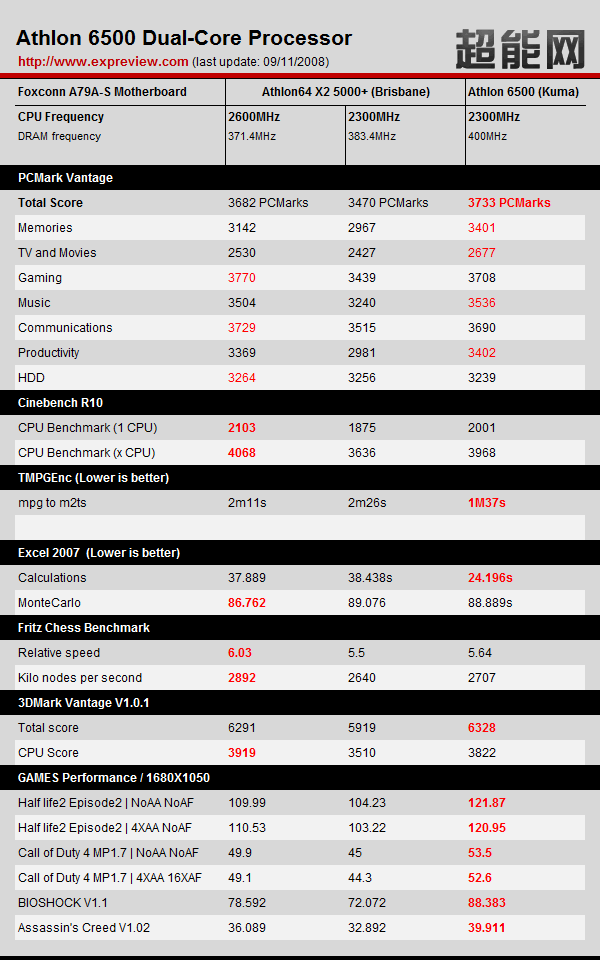
Kuma 6500'ün ilk testleri yayınlandı!
|
saidakkas · İşlemci altına konu açtı.
16 yıl
Eski Intel mühendisi, AMD’nin yeni CEO’su Dirk Meyer’la röportaj
|
saidakkas · İşlemci altına konu açtı.
16 yıl
Kuma 6500 CPU-Z göründü!
|
saidakkas · İşlemci altına konu açtı.
16 yıl
Atom N330 Dual Core, doğal Dual Core tasarım değil mi?
|
saidakkas · İşlemci altına konu açtı.
16 yıl
300mm wafer üzerinde CPU / GPU zar hesapları
|
Hakkında
Konum: Kocaeli,Derince
Forum İmzası:
Forum İkinci El İmzası:
Hakkımda:
| Haber arşivime ulaşmak için tıkla6DD4692A52D24BF9B3145896A483369B.jpg |
Resimler
Temel Bilgiler ve İstatistikler
Aktiflik: Şu anda DH'de değil
Son Giriş: 2 yıl önce
Son Mesaj Zamanı: 12 yıl
Mesaj Sayısı: 3.672
Gerçek Toplam Mesaj Sayısı: 3.928
İkinci El Bölümü Mesajları: 34
Konularının görüntülenme sayısı: 5.274 (Bu ay: 51)
Toplam aldığı artı oy sayısı: 1 (Bu hafta: 0)
En çok mesaj yazdığı forum bölümü: Donanım / Hardware
Son Giriş: 2 yıl önce
Son Mesaj Zamanı: 12 yıl
Mesaj Sayısı: 3.672
Gerçek Toplam Mesaj Sayısı: 3.928
İkinci El Bölümü Mesajları: 34
Konularının görüntülenme sayısı: 5.274 (Bu ay: 51)
Toplam aldığı artı oy sayısı: 1 (Bu hafta: 0)
En çok mesaj yazdığı forum bölümü: Donanım / Hardware
Mesajları
İkinci El Referansları